A unified abstraction layer that puts every LLM provider behind a single API — and a desktop agent that lets any spare laptop or workstation join the local inference pool over WebSocket.
Single-vendor LLM strategies mean betting on one roadmap and one pricing model. Meanwhile, on-prem GPUs and laptop NPUs sit unused while cloud bills climb. Multi-provider integration is custom plumbing for every new agent.
What We Built
One API + a local-pool agent
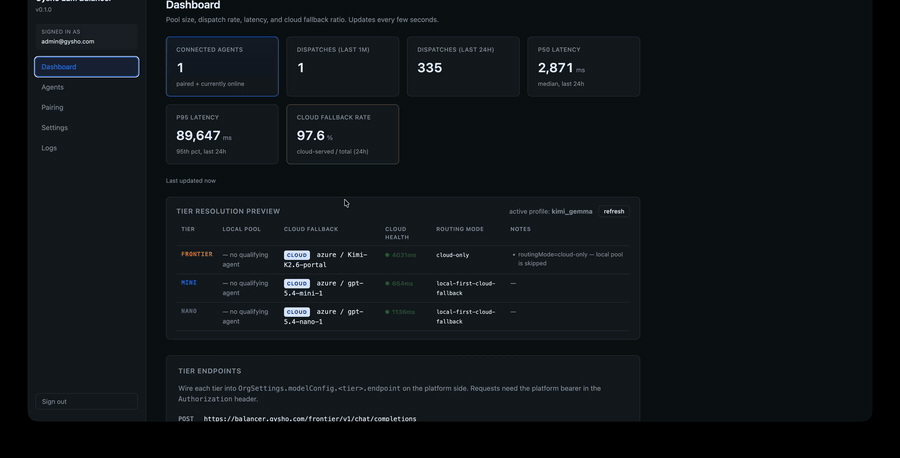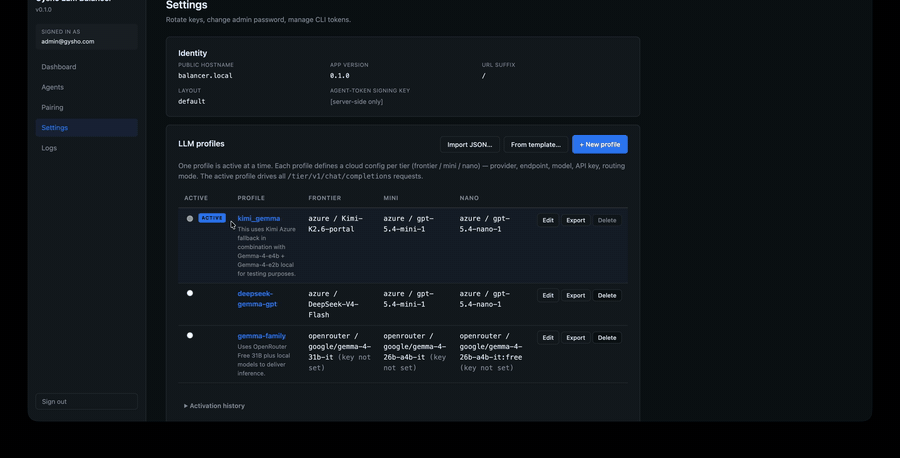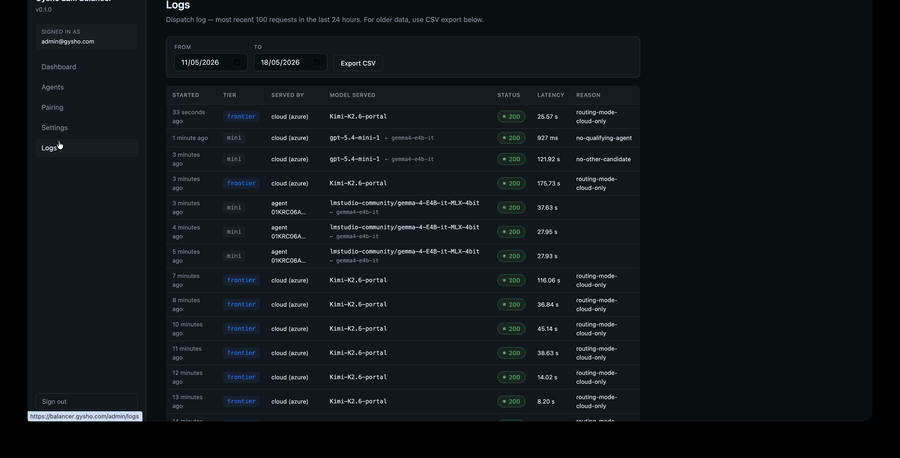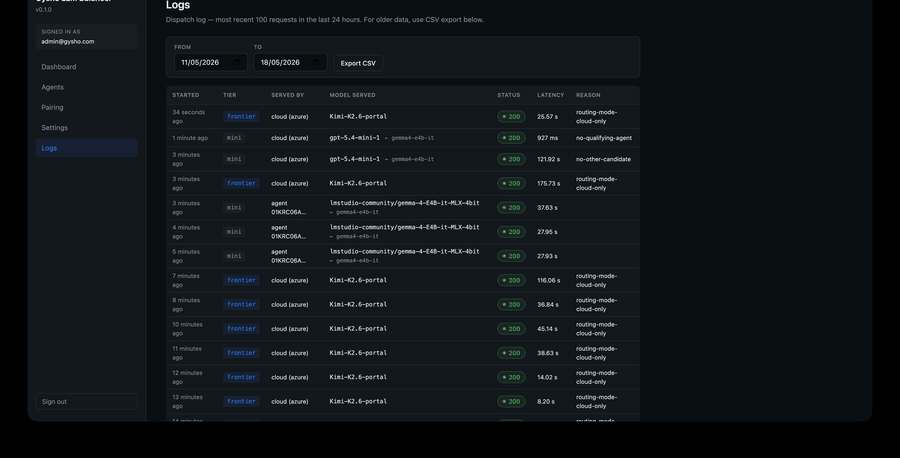
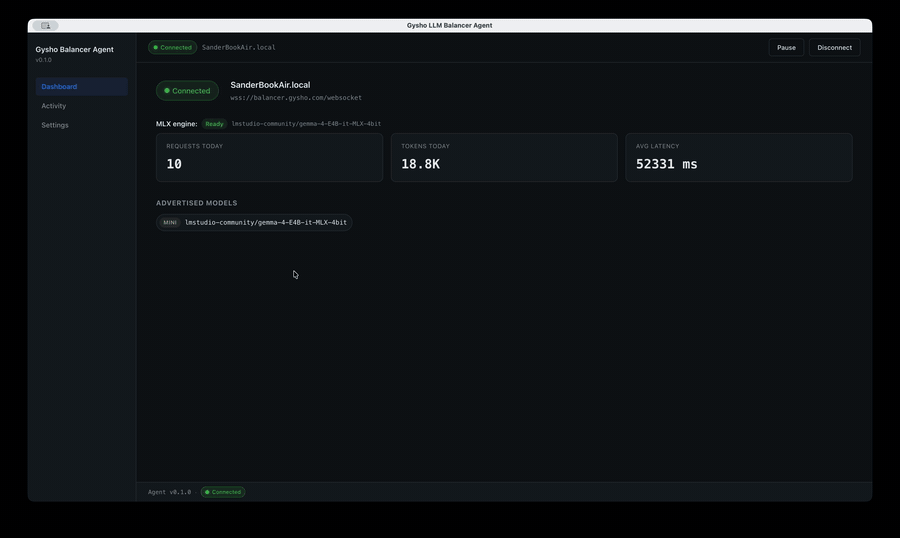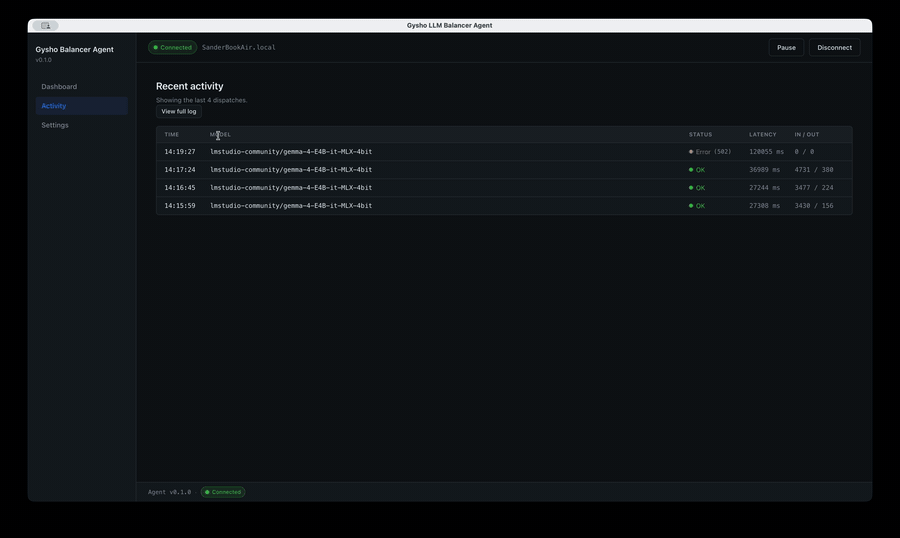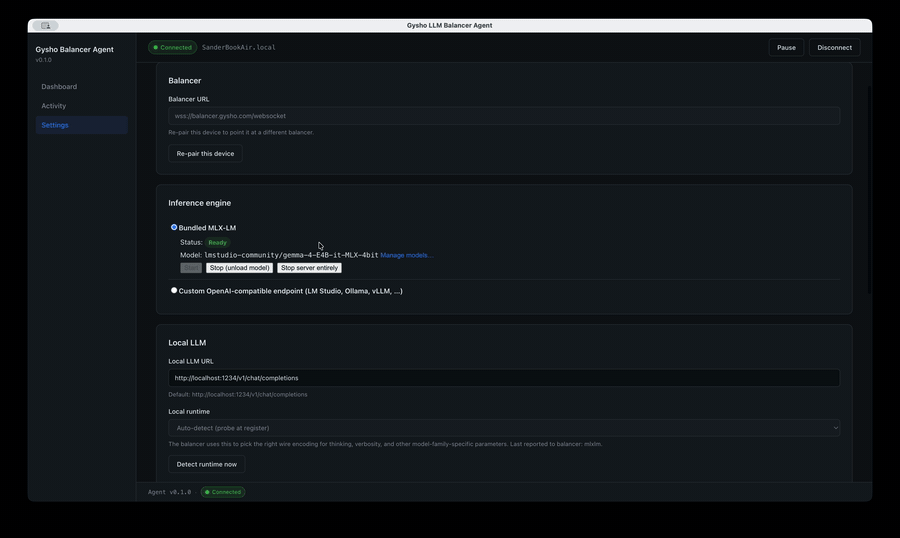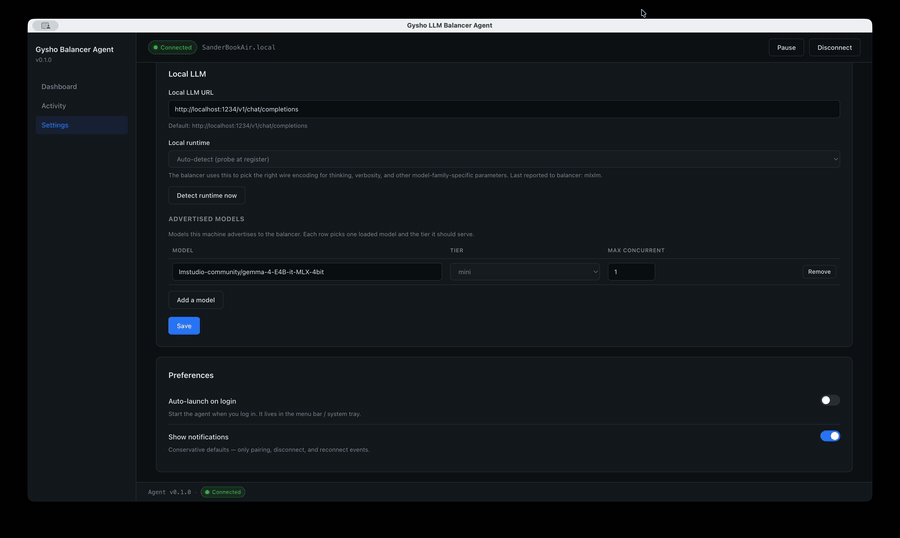
The Balancer normalises requests across Anthropic, OpenAI, Azure, OpenRouter, and any local model — routing by cost, latency, sovereignty, or policy. The desktop Agent lets any spare laptop or workstation register itself as a local-inference node over WebSocket, advertising its MLX models.
The Outcome
Swap models. Reclaim hardware. See the bill.
Provider switches are config, not code. Local capacity shifts on-prem by policy. Every dispatch is logged with cost, latency, and routing reason — AI spend becomes a number you can govern, not a surprise on the invoice.